
由希尔贝壳主办的第四届Kaldi线下交流会在京圆满结束
Kaldi线下交流会从2015年开始经过了三届的成功举办,一届比一届精彩,一届比一届丰富,同时也得到了广大语音界朋友的青睐和认可,就在2019年的美丽秋色中第四届Kaldi线下交流会在北京召开。

▲希尔贝壳CEO卜辉在会上对往届会议做回顾

▲第四届Kaldi线下交流会

▲交流会现场
会议开场及启动
会议开场由AISHELL CEO卜辉先生做了往届会议的说明,并邀请本次会议的协办方小米智能科技的集团副总裁、集团技术委员会主席崔宝秋作为嘉宾发言正式启动会议议程。

崔宝秋总讲到“小米的技术发展历程以及在开源的工作,希望以小米的力量来团结和拉上中国的互联网企业把开源力量推向世界。很荣幸Kaldi之父Dan Povey在近期宣布加入小米,Dan希望小米能够和他一同推进Kaldi的开源。小米已经在开源的路上也一直在,会一直为Kaldi社区做贡献,不只是技术的开源,在数据上也会做开放共享。在这方面卜辉、AISHELL做的很不错。拥抱开源是过去7、8年来,小米工程文化的重要组成部分。我们会坚持不断推动语音的开源开放,也离不开今天在座大家一起的努力。随着科技的进步,也希望能够不断实现小米的远景,让更多的人能够享受科技带来的美好生活,做感动人心、价格厚道的好产品。最后预祝本届大会顺利召开。”同时小米语音技术负责人王育军也做了小爱同学在语音产品端的成绩报告,并表达“实验室会一直在语音识别、语音合成、语音增强做前沿的技术研究,希望小米的成品更丰富。”
各位嘉宾的精彩报告、交流及赛事颁奖
会议中各位嘉宾也作了精彩的报告
谢磊:西北工业大学·教授
TOPIC:Recent Progresses on Speech Processing @NPU-ASLP

▲谢磊

谢老师以一段在线中英文混合识别和基于深度学习的智能降噪展示开始了报告内容。他的报告分享了西工大音频语音与语言处理研究组近期在端到端语音合成、语音分离、基于对抗样本的鲁棒语音识别与关键词检出等三方面的最新研究成果。在端到端语音合成方面,他指出在端到端框架和神经声码器的帮助下,语音合成的保真度(Fidelity)在限定领域已经达到了接近真人的效果,但是在稳定性、自然度上还有一定的提升空间。在梳理近期在稳定性、自然度上的工作之后,他重点介绍了可控性(controllability)的进展,特别是情感强度可控性的成果,并展示了语音合成效果。之后,他指出语音识别的目标已经往解决更为复杂的应用问题(如鸡尾酒会效应)逐步推进,其中语音分离是一项关键性任务。在这方面,他介绍了实验室近期在结合基频信息进行同性语音分离、结合视觉信息进行音视频多模态语音分离方面的研究工作。最后,谢老师介绍了基于深度学习模型的弱点,如何利用对抗样本更为有效的进行数据增广来提升语音识别、关键词检出的鲁棒性的工作。在三方面工作介绍的最后,谢老师都提出了对技术未来发展的方向个人看法。

冯大航:声智科技联合创始人&CTO
TOPIC:基于实践如何提升语音唤醒功能

▲冯大航
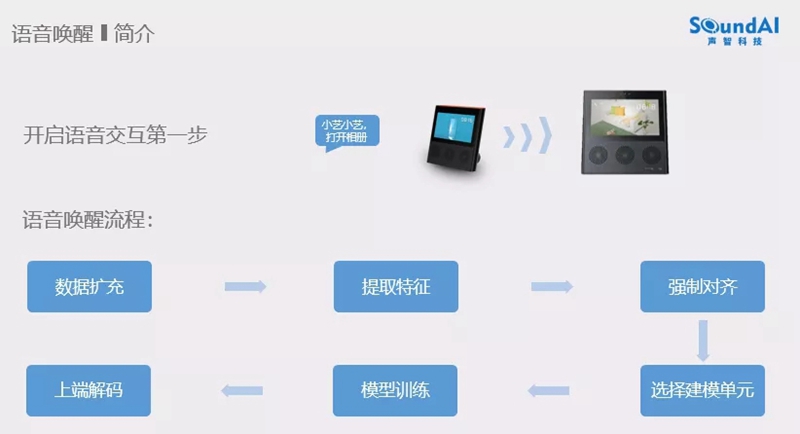
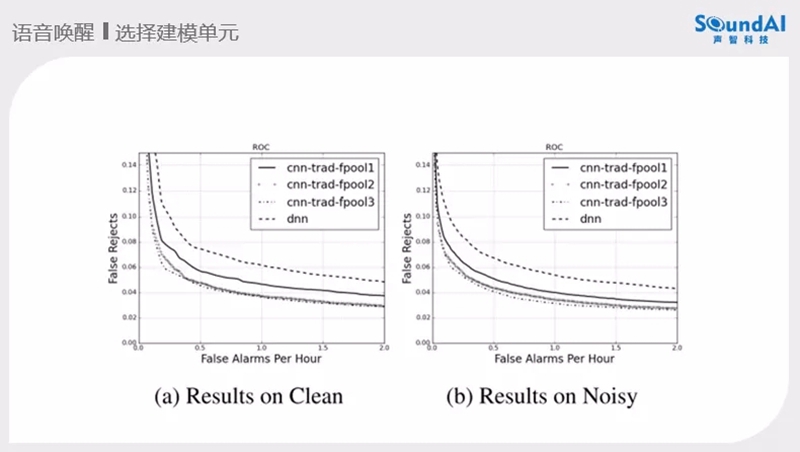
声智科技一直在唤醒的技术上做研究,冯大航也分享了近三年的工作。冯大航表示“当前的技术开源环境很好,Kaldi的开源使很多人共同在做语音技术的研究,AISHELL2的开源让语音识别变的很轻松。对于唤醒最早的工作是针对一些关键词做一些检索,再后来就是出现在手机端的唤醒亮屏。现在看来,这个工作还是简单了些,对于智能音响以及智能设备上实现一个由近端到远端的唤醒识别还是要跨越很多技术。产品的多样化使产品经理在技术落地上不断的提出需要挑战的需求,在低db环境下做到有效的识别性能。唤醒这块的工程实践很重要,由唤醒词的数据开始做扩充,体征提取、强制对齐、选择建模、模型训练、上端解码整个流程的稳定。强制对齐需要一个好的声学模型,也可以考虑用AISHELL2训练一个模型做对齐。但是做到好的性能需要在每个点做细致的打磨。建模单元的选择也很自由,在端上的计算原因,计算的网络结构很重要,CNN和DNN的参数调整以及性能的对比。例如google的实验结果。上端解码大多的方法为后验概率平滑的方法和识别两条路径的分差。在调参的工作上还是很复杂的,需要很多的研究。数据扩充在传统的扩充方式上假定的条件还是不够充足,在单麦和多麦的仿真方法还要考虑更多的空间信息。”最后冯大航也阐述了未来在唤醒技术上的趋势“模型小型化、云端的二次确认、前端阵列信号处理与唤醒的深度融合以及尽可能少的唤醒词录音数据达到比较好的效果”
张俊博:葡萄智学语音技术负责人
TOPIC:发音良好度(GOP)基于Kaldi的实现

▲张俊博
张俊博作为一个语音技术研究的老兵分享了目前在做的一些工作,也作为Kaldi的积极贡献者讲述了在Kaldi环境下做发音评测的研究。在GOP-GMM上做发音错误检测的工作上,张俊博也做了开源的工作。

发音良好度就是一个后验概率,认为phone的先验概率是相同的,目标音素对语音的影响有多大做判断。难点在不是对帧的分析是一段的分析,phone的分布不平均,以最大值代替求和。最后张俊博分享了在GitHub上开源项目的分享,也表达了语音技术在教育行业里起到的AI的重要功能,也希望大家多关注整个行业。

AISHELL &AISHELL Foundation
作为AISEHLL& AISHELL Foundation的创始人,卜辉在AISHELL数据+技术的开源工作上做了报告。卜辉讲到“技术落地,数据先行已经成为AI产品落地的模式,在5年前大家是卡在技术落地,需要场景化需要市场验证。然而能够做到产品化的企业和高校还是不多,大家卡在数据上。我们回看openslr上的中文数据开源时间,发现2015年才有中文的数据开源,这已经是相对于英文是落后的。我们AISHELL在2017、2018年分别做了数据+技术的开源,也别是去年AISHELL2的发布,影响了整个中文语音识别技术的发展。我们从CV的数据开源来看,2010年李飞飞老师发布的ImageNet图片量达到1500万张,CV的快速发展离不开ImageNet。那么语音的技术发展同样需要数据开源助力,AISEHLL1&2的全球申请量突破500次。我们希望AISEHLL每次的开源都会给整个产业带来帮助,今天我们带来了今年的开源产品AISHELL-WakeUp-1。在技术上我们近期做的工作是在Kaldi里开源了使用目前openslr上所有中文开源数据做的一个开放语音系统方案。”


付强:阿里巴巴达摩院机器智能语音实验室研究员
TOPIC:语音交互前端信号处理概述

▲付强
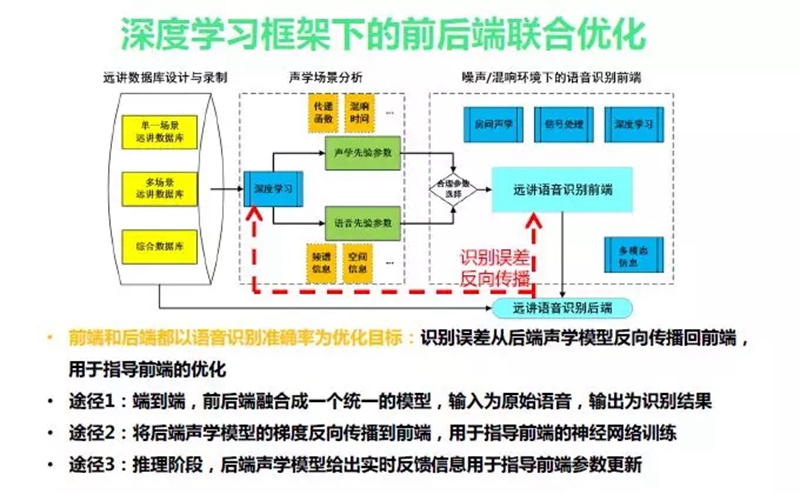
付强老师作为从学术研究到产业研究的代表讲述了语音交互前端的技术研究,付强老师讲到“语音交互的“自然”意味着无约束,怎样达到无约束很是有很多挑战。在远讲(场)交互,目标声源距离拾音设备较远,更易受到声学回声、干扰声源、背景噪声、房间混响等各种不利因素的影响都会改变交互的性能。需要综合运用信号处理、机器学习手段以及融合语义层面的信息来提高目标语音的信噪比,增强后续处理的声环境稳健性。”
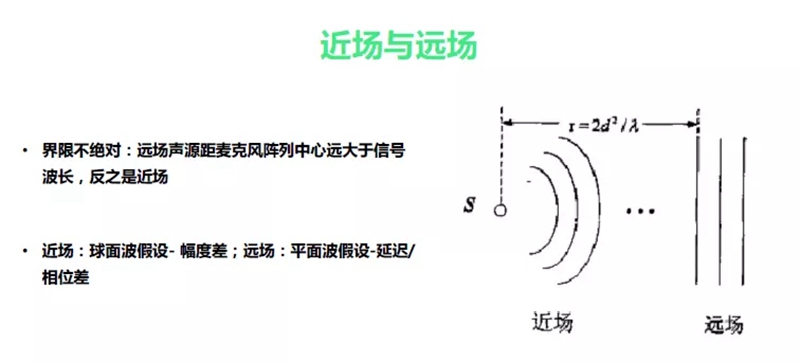
“在车载场景、会议等场景会有不同的幻想,在前端处理还是希望能够克服更多的信号处理问题。需要回声消除、解混响、波束处理、盲源分离。”最后付强老师发表的对信号端处理的问题和趋势“第一极低信噪比、第二多声源干扰、第三移动声源干扰、第四端到端”。
李明:昆山杜克大学·副教授
TOPIC:基于端到端深度学习框架的远场声纹识别

▲李明
李明老师做了关于End-to-End的深度网络学习的说话人识别研究,对领域研究的问题深入讨论了相关技术的发展以及方向。在实验室里目前的研究内容也做了分享。

“提取语音的特征有MFCC、PLP、SDC、PNCC、GFCC、CQCC等的处理区别在不同的应用上要合理的选取,文本无关的处理需要做phoneme的处理,在情感识别上选择Open Smile一些段的体征,Speech attributes做副信息的体征处理。当前的新型体征例如Modified Group Delay信息。”
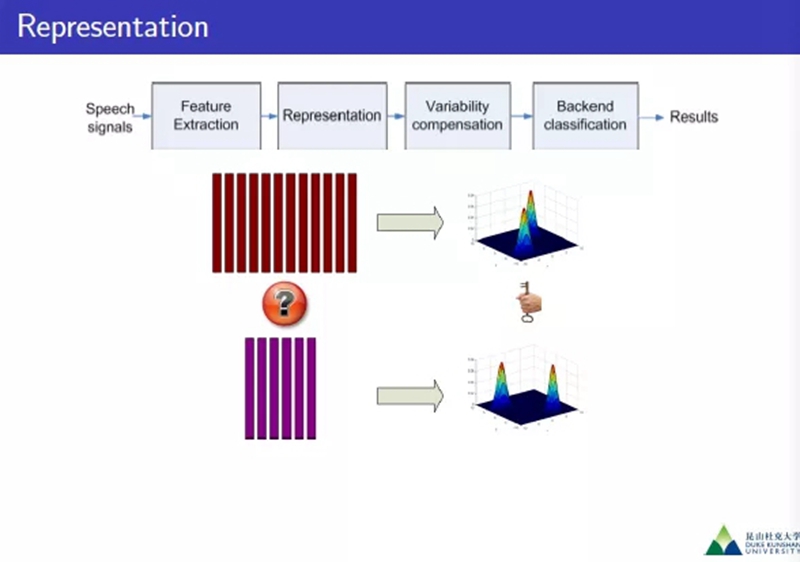
“在网络机构上有FF-DNN、RNN/LSTM、CNN、TDNN这些结构,Data Augmentation通常加noise、music、babble、reveberation这些,还有Speech perturbation、Generative adversarial network这些方法。增强模型的鲁棒性,考虑空间的环境、前验的模型、鲁棒模型等问题。”

圆桌会议
下午的圆桌讨论以“人机语音交互是否必须要先唤醒和离线语音技术在本地端上的实现是否未来的趋势”两个论题做了精彩的讨论。来自猎户星空&Kaldi群主吴本谷、小米智能科技的语音负责人王育军、知存科技CEO王绍迪、快商通语音技术负责人李稀敏,四位嘉宾做了讨论交流。

▲圆桌会议,从左至右分别为吴本谷、王育军、王绍迪、李稀敏、卜辉
AISHELL Speaker Verification Challenge 2019竞赛颁奖
本届Kaldi线下交流会加入了赛事环节,由希尔贝壳、昆山杜克大学、CCF语音对话与听觉专业组、AISHELL Foundation合办的AISHELL Speaker Verification Challenge 2019在会上做了赛事报告以及获奖公布。Track1&2的123名分别由小米智能科技、华南理工大学、中科院声学所获得,会上也做了很精彩的系统介绍报告。
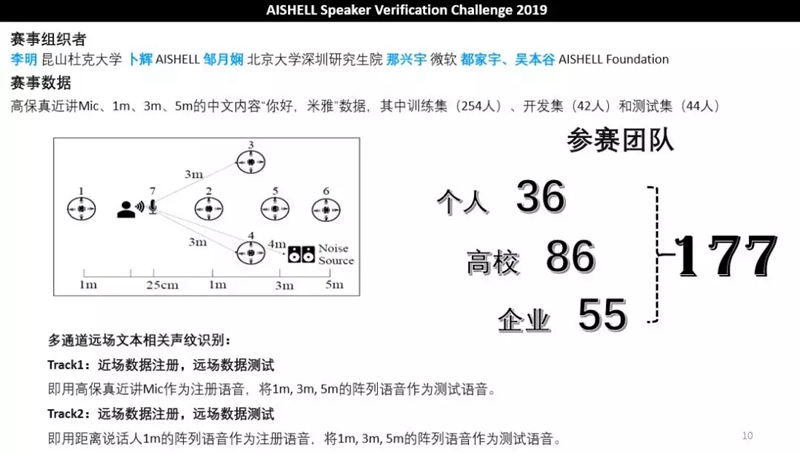
▲本届AISHELL-SVC竞赛情况




▲获奖者

